【置顶】 留言请点击友链留言室或者在文章底部留言

官网
http://rocketmq.apache.org/release_notes/release-notes-4.3.2/
中文文档
https://rocketmq-1.gitbook.io/rocketmq-connector/quick-start/qian-qi-zhun-bei/dan-ji-huan-jing
idea调试工具
https://www.jetbrains.com/help/idea/2019.1/debug-tool-window.html
https://github.com/DillonDong/notes
Windows环境下安装RocketMQ
一.预备环境
1.系统
Windows
2. 环境
JDK1.8、Maven、Git
二. RocketMQ部署
1.下载
1.1地址:http://rocketmq.apache.org/release_notes/release-notes-4.3.0/
1.2选择‘Binary’进行下载
1.3解压已下载工程
2. 配置
2.1 系统环境变量配置
变量名:ROCKETMQ_HOME
变量值:MQ解压路径\MQ文件夹名
eg、ROCKETMQ_HOME=D:\dev\rocketmq-all-4.3.0-bin-release
3. 启动
3.1 启动NAMESERVER
Cmd命令框执行进入至‘MQ文件夹\bin’下,然后执行‘start mqnamesrv.cmd’,启动NAMESERVER。成功后会弹出提示框,此框勿关闭。
3.2 启动BROKER
Cmd命令框执行进入至‘MQ文件夹\bin’下,然后执行‘start mqbroker.cmd -n 127.0.0.1:9876 autoCreateTopicEnable=true’,启动BROKER。成功后会弹出提示框,此框勿关闭
- 编译启动
用CMD进入‘\rocketmq-externals\rocketmq-console’文件夹,执行‘mvn clean package -Dmaven.test.skip=true’,编译生成。
编译成功之后,Cmd进入‘target’文件夹,执行‘java -jar rocketmq-console-ng-1.0.0.jar’,启动‘rocketmq-console-ng-1.0.0.jar’。 - 测试
浏览器中输入‘127.0.0.1:配置端口’,成功后即可查看。
eg:http://127.0.0.1:8088
基本配置项
1 | server.contextPath= |
java整合MQ
1 |
|
消息消费顺序:全局消息顺序
局部消息顺序
保证局部消息的顺序
只在一个队列保证一个人消费
消费时,同一个OrderId获取到的肯定是同一个队列。
消息存储结构
刷盘机制:同步刷盘
异步刷盘
RocketMQ的消息是存储到磁盘上的,这样既能保证断电后恢复, 又可以让存储的消息量超出内存的限制。RocketMQ为了提高性能,会尽可能地保证磁盘的
顺序写。消息在通过Producer写入RocketMQ的时 候,有两种写磁盘方式,分布式同步刷盘和异步刷盘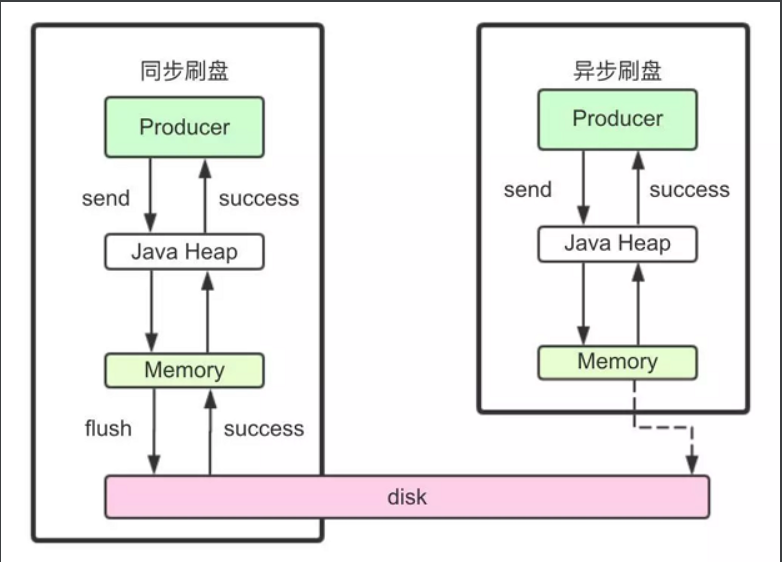
顺序消息消费及时监控处理
对于顺序消息,当消费者消费消息失败后,消息队列 RocketMQ 会自动不断进行消息重试(每次间隔时间为 1 秒),这时,应用会出现消息消费被阻塞的情况。因此,在使用顺序消息时,务必保证应用能够及时监控并处理消费失败的情况,避免阻塞现象的发生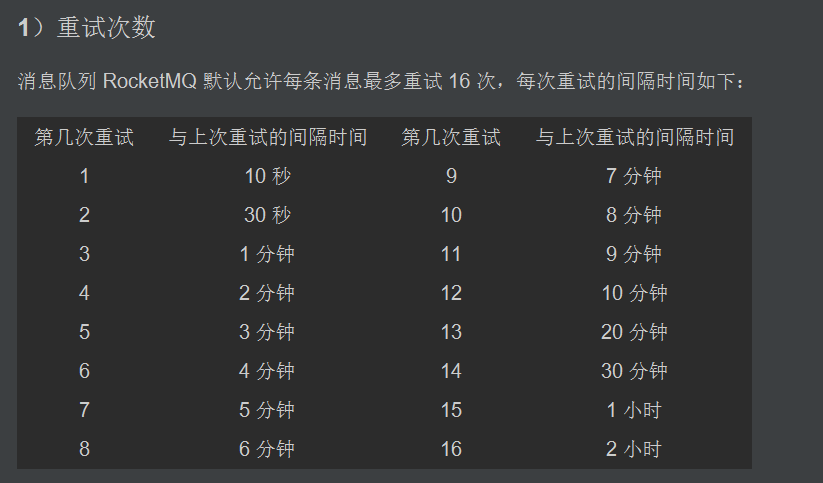
消费幂等:若某操作执行多次或一次对系统产生的结果是相同的,则称该操作是幂等的
例如支付场景,因为网络原因导致二次消费,会不会造成重复扣款
RocketMq的文件存储系统有两点优化以保证性能:
消息存储(顺序写):RocketMQ的消息用顺序写,保证了消息存储的速度。目前的高性能磁盘,顺序写速度可以达到600MB/s,
超过了一般网卡的传输速度,但是磁盘随机写的速度只有大概100KB/s
消息发送(零拷贝):将本机磁盘文件的内容发送到客户端需要进行多次复制,比如从磁盘复制数据到内核态内存;从内核态内存复制到用户态内存;从用户态内存复制到网络驱动,>最后从网络驱动复制到网卡中。RocketMq采用Java中零拷贝的技术,让从内核态内存复制到用户态内存这一步省略,直接赋值到网络驱动中
零拷贝技术有个限制是不能超过2G,所以RocketMQ默认设置单个CommitLog日志数据文件为1G
RokectMq架构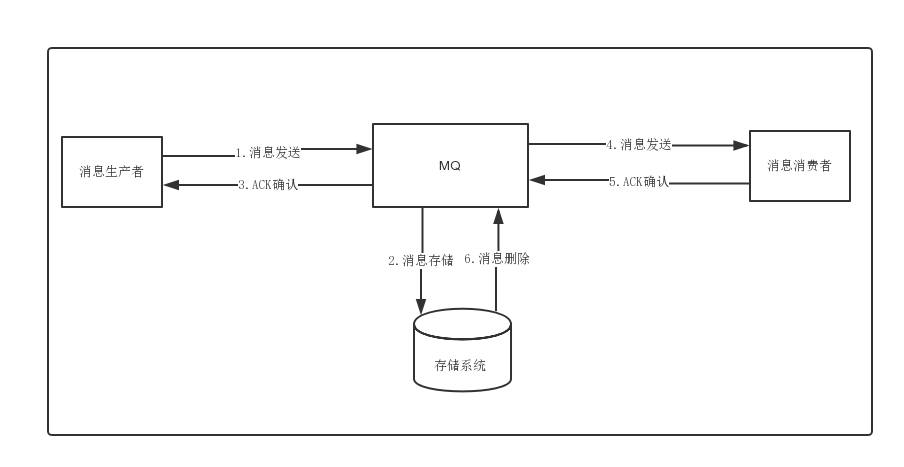
存储结构是什么样的?
RocketMQ消息的存储是由ConsumeQueue和CommitLog配合完成的
CommitLog:消息真正的物理存储文件是CommitLog,默认一个文件一个G,存储的是Topic,QueueId和Message,一个存储满了会自动创建一个新的。
ConsumeQueue:是消息的逻辑队列,类似数据库的索引文件,存储的是指向物理存储的地址,为了加快消息的读取速度。消费者消费某条消息时,先查询索引获取CommitLog的对应的物理地址。每个Topic下的每个Message Queue都有一个对应的ConsumeQueue文件,文件很小,通常会加载到内存中。如果该文件丢失或者损坏,可以通过CommitLog恢复
IndexFile:也是个索引文件,为了消息查询提供了一种通过key或时间区间来查询消息的方法,这种通过IndexFile来查找消息的方法不影响发送与消费消息的主流程
如何保证消息不丢失?
RocketMq提供消息持久化机制,消息的刷盘策略分为同步刷盘和异步刷盘。同步刷盘即刷盘成功后再返回一个成功信息,能够保证数据一定保存成功,但是会降低系统吞吐量,异步刷盘与同步刷盘相反,我一般会采用同步刷盘的策略来保证消息不会丢失。
RocketMq采用的文件系统存储而不是关系型数据库存储,因为在一般情况下文件系统的性能是比数据库性能高的
而RocketMq为了提高文件系统的读写的高性能,做了两点优化。第一点是采用顺序写的方式,这样可以大大提高磁盘写的性能。第二点采用了零拷贝,原来的文件读取流程是:从磁盘复制数据到内核态内存;从内核态内存复制到用户态内存;从用户态内存复制到网络驱动,最后从网络驱动复制到网卡中发送,零拷贝则省去了从内核态内存复制到用户态内存的这一过程,提高了读取的性能,但是零拷贝对文件大小有要求,所以RocketMq的持久化文件commitlog默认为1G。
commitlog是存储了RocketMq的消息等核心信息,除此之外,还提供可一个ConsumeQueue作为持久化文件的索引,提高查询的效率,一般文件比较小,都是加载在内存中。除了ConsumeQueue之外,还会存储一个IndexFile文件,用来提供针对某一个key或者时间区间的查询。
负载均衡
Producer负载均衡
Producer端,每个实例在发消息的时候,默认会轮询所有的message queue发送,以达到让消息平均落在不同的queue上。而由于queue可以散落在不同的broker,所以消息就发送到不同的broker下
Consumer负载均衡
如果consumer实例的数量比message queue的总数量还多的话,多出来的consumer实例将无法分到queue,也就无法消费到消息,也就无法起到分摊负载的作用了。所以需要控制让queue的总数量大于等于consumer的数量。
消费者的集群模式–启动多个消费者就可以保证消费者的负载均衡(均摊队列)
默认使用的是均摊队列:会按照queue的数量和实例的数量平均分配queue给每个实例,这样每个消费者可以均摊消费的队列
消息重试机制
1. 顺序消息的重试
对于顺序消息,当消费者消费消息失败后,消息队列 RocketMQ 会自动不断进行消息重试(每次间隔时间为 1 秒),这时,应用会出现消息消费被阻塞的情况。
因此,在使用顺序消息时,务必保证应用能够及时监控并处理消费失败的情况,避免阻塞现象的发生。
2. 无序消息的重试
对于无序消息(普通、定时、延时、事务消息),当消费者消费消息失败时,您可以通过设置返回状态达到消息重试的结果。
无序消息的重试只针对集群消费方式生效;广播方式不提供失败重试特性,即消费失败后,失败消息不再重试,继续消费新的消息。
消息队列 RocketMQ 默认允许每条消息最多重试 16 次,将会在接下来的 4 小时 46 分钟之内进行 16 次重试,如果依然失败就会进入死信队列。
一条消息无论重试多少次,这些重试消息的 Message ID 不会改变。
也可以通过配置,让其不再重试,但是不建议这样
1 |
|
消费幂等
消息队列 RocketMQ 消费者在接收到消息以后,有必要根据业务上的唯一 Key 对消息做幂等处理的必要性。
1. 什么时候产生重复消息?
在互联网应用中,尤其在网络不稳定的情况下,消息队列 RocketMQ 的消息有可能会出现重复,这个重复简单可以概括为以下情况:
发送时消息重复
当一条消息已被成功发送到服务端并完成持久化,此时出现了网络闪断或者客户端宕机,导致服务端对客户端应答失败。 如果此时生产者意识到消息发送失败并尝试再次发送消息,消费者后续会收到两条内容相同并且 Message ID 也相同的消息。
消费时消息重复
消息消费的场景下,消息已投递到消费者并完成业务处理,当客户端给服务端反馈应答的时候网络闪断。 为了保证消息至少被消费一次,消息队列 RocketMQ 的服务端将在网络恢复后再次尝试投递之前已被处理过的消息,消费者后续会收到两条内容相同并且 Message ID 也相同的消息。
负载均衡时消息重复(包括但不限于网络抖动、Broker 重启以及订阅方应用重启)
当消息队列 RocketMQ 的 Broker 或客户端重启、扩容或缩容时,会触发 Rebalance,此时消费者可能会收到重复消息。
2. 处理方式
因为 Message ID 有可能出现冲突(重复)的情况,所以真正安全的幂等处理,不建议以 Message ID 作为处理依据。 最好的方式是以业务唯一标识作为幂等处理的关键依据,而业务的唯一标识可以通过消息 Key 进行设置:
1 |
|
订阅方收到消息时可以根据消息的 Key 进行幂等处理:
1 |
|
接下来,就需要根据业务进行处理:
拿个数据要写库,先根据主键查一下,如果这数据都有了,你就别插入了,只需要更新一下;或者可以设置一个唯一索引
如果是写Redis,每次操作都是set,天然可以保证幂等性
如果不是上面两种场景,需要让生产者发送每条数据的时候,里面加一个全局唯一的id,类似订单id之类的东西;消费者需要先根据这个id去比如redis里查一下,之前消费过吗?如果没有消费过,你就处理,然后这个id写redis。如果消费过了,那你就别处理了,保证别重复处理相同的消息即可。
如何解决消息积压的问题?
这个可能出现在消费端出了问题,不消费了,或者消费的极其极其慢,导致大量的消息无法消费,最后消息队列集群的磁盘都快写满了
首先最重要的就是修复消费者,接着最大的问题就是在消费者重启后,如何快速处理积压的消息?
新建一个topic,临时建立好原先10倍或者20倍的queue数量
接着扩容临时的consumer,此时消费速度是原来的十几倍
等快速消费完积压数据之后,得恢复原先部署架构,重新用原先的consumer机器来消费消息
如何设计一个Mq?
是上面内容的一个总结,需要分点进行设计
扩展性
生产者的扩展性
消息队列的扩展性
消费者的扩展性
高可用性
如何设计刷盘策略?
如何保证消息0丢失?
如何保证在其中有机器宕机时,保障服务可用?
消息重试机制
当一个消息没有被消费时,如何进行重试,保证消息一定被消费?
当消费端不可用时,如何保证消费端重启后,依然可以消费消息?
心跳检测机制
如何检测生产者、消息队列和消费者是否宕机?
负载均衡模式
如何做到消息生产以及消费的负载均衡?
顺序消息
如何实现顺序消息?

